Follow Novatech

In enterprise AI implementations, the bottleneck rarely lies in the model itself—it’s in context engineering. Vast volumes of business-critical data are trapped in unstructured formats: PDFs, PPTs, Excel spreadsheets, images, and HTML files. The ability to reliably convert scattered, heterogeneous, and constantly updated enterprise data into LLM-recognizable context is the make-or-break step for successful AI adoption.
The Limitations of Traditional RAG in Enterprises
Traditional Retrieval-Augmented Generation (RAG) systems often struggle to meet enterprise demands due to three core challenges:
- Siloed Data Sources
Enterprise data is spread across dozens of systems—ERP platforms, internal wikis, cloud storage drives, and more. Adapting RAG to connect these disjointed sources incurs high integration costs. - Loss in Heterogeneous Data Parsing
Multimodal content (tables, charts, formulas) is frequently lost during processing. Rigid text chunking also breaks the logical flow of documents, undermining context accuracy. - Black-Box Processing
Teams cannot pinpoint errors in parsing, chunking, or vectorization. Debugging becomes a time-consuming, trial-and-error process with no clear visibility into root causes.
Introducing Dify Knowledge Pipeline
As a leading enterprise-grade Agentic AI solution provider in China, Dify addresses these pain points with its Knowledge Pipeline—a visual, configurable workflow that gives enterprises full control over the end-to-end transformation of raw data into high-quality LLM context.
This pipeline delivers three key value propositions:
- Value 1: Business-Technical Collaboration
Business experts can directly debug retrieval processes via a visual interface, eliminating communication gaps with technical teams.
- Value 2: Cost Reduction & Efficiency Gains
Reusable templates (e.g., contract review, customer service knowledge bases) reduce redundant setup and maintenance work.
- Value 3: Flexible Technology Selection
Every part (OCR, parsing, vector databases) can be replaced on-demand. Enterprises always use the industry’s best tools without being locked into a single vendor.
Key Capabilities of Dify Knowledge Pipeline
1. Visual Canvas-Based Orchestration
- Building on Dify’s intuitive Workflow canvas, the pipeline breaks RAG’s ETL (Extract, Transform, Load) process into modular nodes—including data source integration, document parsing, and chunking strategies.
- It also supports embedding Workflow logic nodes, Code nodes, and LLM nodes. This enables flexible customization (e.g., sensitive information redaction, entity extraction) through a combination of "rule-based code cleaning + LLM-powered content enhancement."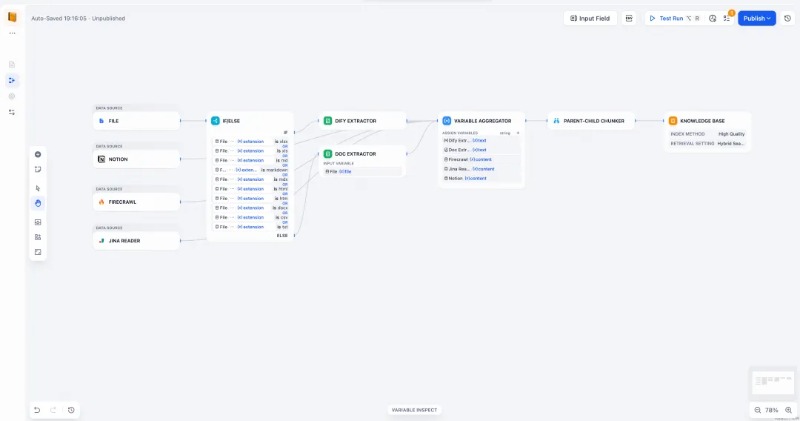
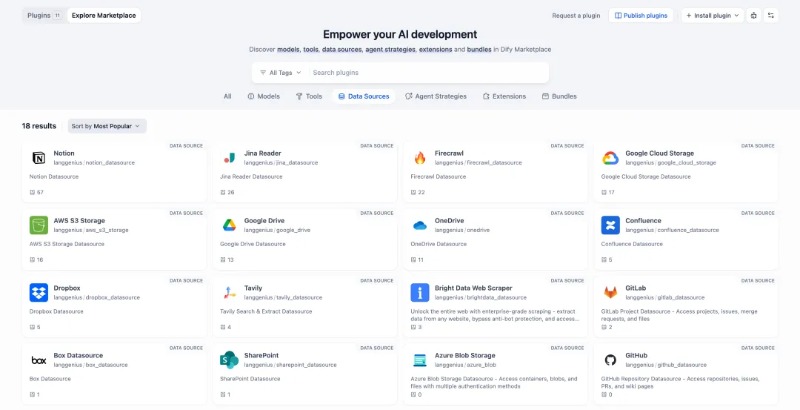
2. Plug-and-Play Integration for All Data Sources
Through Data Source plugins, enterprises can connect to multiple data types with one click—no custom development required. Custom plugin extensions are also supported to meet unique business needs.
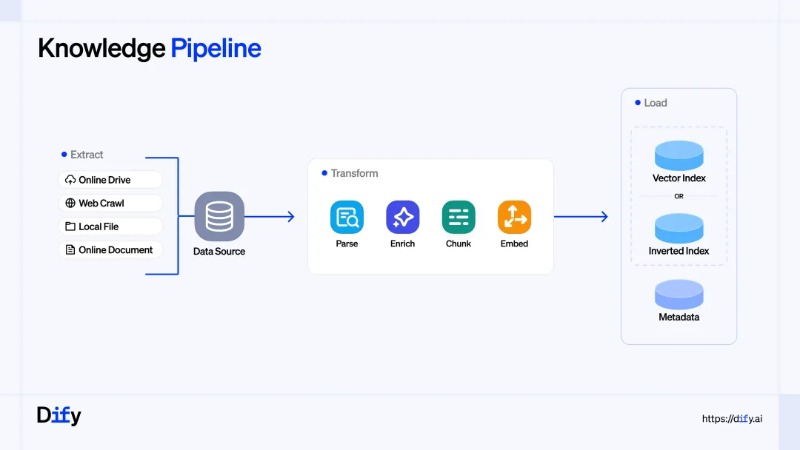
3. Modular, Swappable Data Processing Pipeline
Data processing is split into standardized nodes, each replaceable via plugins to fit specific requirements:
- Extract: Parallel integration of multiple data sources, with unified handling of multimodal content (text, images, audio, video).
- Transform (Core Stage):
Parse: Select the optimal parser for each file type. Support for parallel parsers (e.g., OCR for scanned documents, table restoration, PPT text box ordering correction) ensures no information is lost.
Enrich: Use LLMs to generate summaries, classify tags, and redact sensitive data—boosting content quality.
Chunk: Three strategies for different scenarios:General (for broad use cases)、Parent-Child (for precise position in long documents)、Q&A (for structured question-answering),This has improved retrieval accuracy by 35% in customer service scenarios.
- Embed: Switch embedding models flexibly based on cost, language support, and dimensionality needs.
- Load: Support for "high-quality vector indexes + cost-effective inverted indexes." Configurable metadata tags enable precise filtering and permission control.
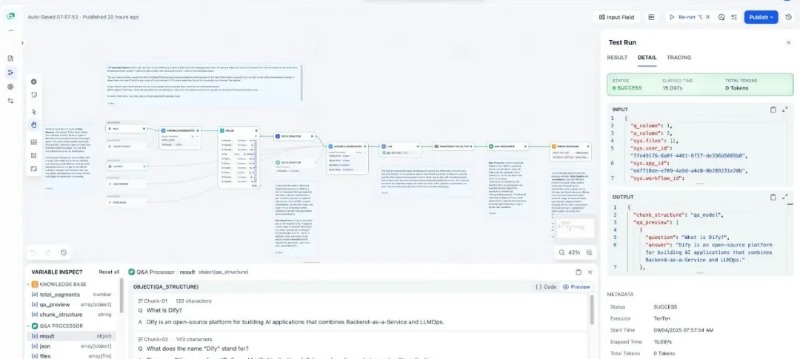
4. Observable Debugging Tools
- Test Run: Execute the pipeline node-by-node to verify if input/output at each step meets expectations.
- Variable Inspect: Real-time monitoring of intermediate variables and context. Quickly identify parsing errors, chunking anomalies, or missing metadata.
5. 7 Ready-to-Use Templates
Pre-built templates cover common enterprise use cases, significantly lowering the barrier to entry for teams new to RAG.

6. Multimodal Processing Breakthroughs
- MinerU Plugin Integration: Extract images/charts from PDFs, Word docs, PPTs, and scanned files—with generated accessible URLs.
- Mixed Text-Image Output: LLMs can directly reference charts from documents in their responses, solving the "chart invisibility" issue in traditional RAG.
- Enhanced OCR: Supports text recognition in 84 languages for scanned documents, with accurate handling of formulas and garbled PDFs.
Plugin Ecosystem & Efficiency Optimization
The pipeline offers full RAG lifecycle plugin coverage:
- Connectors (Data Sources): Integrate with mainstream platforms like Google Drive, Notion, and Confluence.
- Ingestion (Parsing Tools): Support for LlamaParse, Unstructured, and OCR tools (e.g., MinerU).
- Storage: Connect to leading vector databases (Qdrant, Weaviate, Milvus, Oracle) with support for custom configurations of enterprise or open-source versions.